
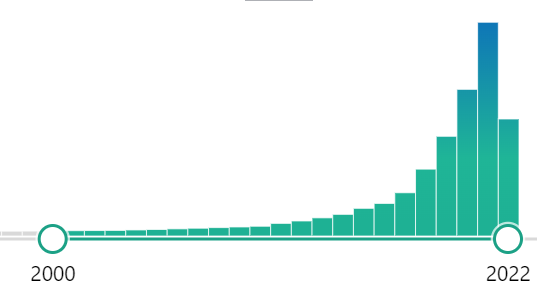
機械学習という言葉をご存知でしょうか?恐らく多くの人が「Yes!」と答えるかと思います。機械学習は画期的かつ汎用性の高い先端テクノロジーであり、先進国を中心にさまざまな機械学習を用いた研究の発表や新サービスの登場が後を絶ちません。このトレンドは医療業界においても同様です。医療業界における機械学習の注目度を反映するデータの1つに生命科学や生物医学に関する参考文献や要約を掲載する検索エンジン(PubMed)の論文投稿数があります。PubMedで「Machine Learning」または「Deep Learning(Machine Learningの下位語)」で検索した結果は以下の通りです。機械学習に関する論文投稿数は急激に伸び続けており、昨年は総投稿数が32,293件にのぼり一日に平均約88件もの論文が新しく投稿されていたことが分かります。このように医療分野における機械学習技術を用いた研究は日夜進歩しており、次世代の医療において機械学習がいかに重要なキーワードになるかがご理解いただけると思います。
参考URL:https://pubmed.ncbi.nlm.nih.gov/?term=Machine+Learning+OR+Deep+Learning&timeline=expanded
冒頭で述べたように機械学習について耳にしたことがある人は多いと思います。では、機械学習の定義や仕組みについてはどうでしょうか?この問いに対しては「No…」と答える人も一定数いるのではないかと思います。機械学習はデータ分析手法の1つを指し、その定義は、「コンピュータがデータから自動でルールやパターンを学習し、学習したルールやパターンをもとに新しいデータに対して判断・予測を行うこと」とされています。従来の手法と異なる点は、ルールやパターンを人が設計するのではなく、コンピュータが自動で行っているという点です。これにより、従来の統計学によるデータ分析では見つけられなかった ” 新しい発見 ” や、データドリブンな学習による ” 高精度な予測モデルの構築 ” が可能になりました。また機械学習は解析対象について専門的な知識を有する人財の介入なしにデータを解釈し処理できるので、大量かつ複雑なデータも短時間で分析できるという点でも優れていると言えます。
次に機械学習の大まかな分類とその仕組みについて見ていきます。機械学習はその学習手法に応じて、教師あり学習、教師なし学習、強化学習の3つに対別されます。それぞれの仕組みについて一つずつ確認します。
教師あり学習は、データとそれに対応したラベルの入出力関係を学習し、未知のデータに対するラベルを予測するための学習手法です。データを「問題」、ラベルを「答え」としたときに、大量の問題と答えのセットを与えることで、問題から答えを導く「方程式(=ルールやパターン)」を学習させるイメージです。
教師あり学習で行われるタスクは主に「分類タスク」と「回帰タスク」の二つです。予測する「答え」がカテゴリであるものを「分類タスク」、数値であるものを「回帰タスク」と言います。簡単な例で言うと、分類タスクには腫瘍の良性・悪性の判別、回帰タスクには血糖値の予測などが考えられます。
教師あり学習の学習は、主に「データ変換」「出力データの評価」の2ステップから成り立っています。
まず「データ変換」では、入力データをアルゴリズムに従ってデータ変換します。
次に「出力データの評価」では、データ変換によって得られた出力データ(予測値)がラベルデータ(目的値)とどれほど類似しているかを評価しています。
教師有り学習では、入力データをアルゴリズムごとに設定された一連の演算式によって変換し、出力データの評価が最も高くなる演算式を採用し、これを最終的なモデルに利用しています。
教師なし学習は、データに内在するパターンを学習し、そのデータに関する知見を得るための学習手法です。教師なし学習は、その名の通り教師あり学習と違って、「答え」に当たるラベルデータを学習に必要としないことからその名がつけられています。
教師なし学習で行われるタスクは主に「クラスタリング」、「次元削減」、「表現学習」、「敵対生成」などです。似通った特徴をもつデータをグルーピングするタスクを「クラスタリング」、多変量のデータから相関のあるデータを統合しデータの次元数を削減するタスクを「次元削減」、機械学習を行うのに最適なデータ表現を学習するタスクを「表現学習」、データから特徴を学習し、その特徴を持った新しいデータを生成するタスクを「敵対生成」といいます。
たとえば、クラスタリングは疾患のより詳細な疾患サブタイプの設定、次元削減はゲノム解析、表現学習は医療テキストからの固有表現の抽出、敵対生成は医用画像の生成による学習用データの増幅などへの利用が考えられます。
教師なし学習では、主にデータ間の距離を計算することによってデータの類似性や特性を判断しています。
強化学習は、「環境」に応じて、目的として設定された「報酬(スコア)」を最大化するために、最適な「行動」をさせるための学習手法です。
強化学習は主にロボット制御などに利用されますが、ここでは、医学領域における強化学習の利用例として「強化学習の技術を用いた敗血症患者の最適治療法の提案」について書かれた論文を紹介します。
参考URL:https://www.nature.com/articles/s41591-018-0213-5.pdf
この研究では、強化学習により、バイタルサイン、検査値、輸液、血管圧など48種類の時系列データで設定された患者の状態(環境)において、治療の予後(報酬)を最も良くする処方薬の量やタイミングといった治療方針(行動)を学習している。
臨床医による治療のスコアと学習したモデルによる治療のスコアを比較したところ、臨床医による治療のスコアが56.9 (四分位範囲, 54.7-58.8) で合ったのに対し、学習したモデルによる治療のスコアは 84.5 (四分位範囲, 84.3-87.7) であり、臨床医のスコアを大きく上回る結果となりました。
機械学習の概要を掴んだところで、次に気になってくるのは実際にどう使われているか?ではないかと思います。ここでは、機械学習技術の応用例について、厚生労働省が選定した「保健医療分野における人工知能の活用が期待される重点6領域」に沿って紹介します。
参考URL: https://www.mhlw.go.jp/wp/hakusyo/kousei/17/backdata/01-03-03-10.html)
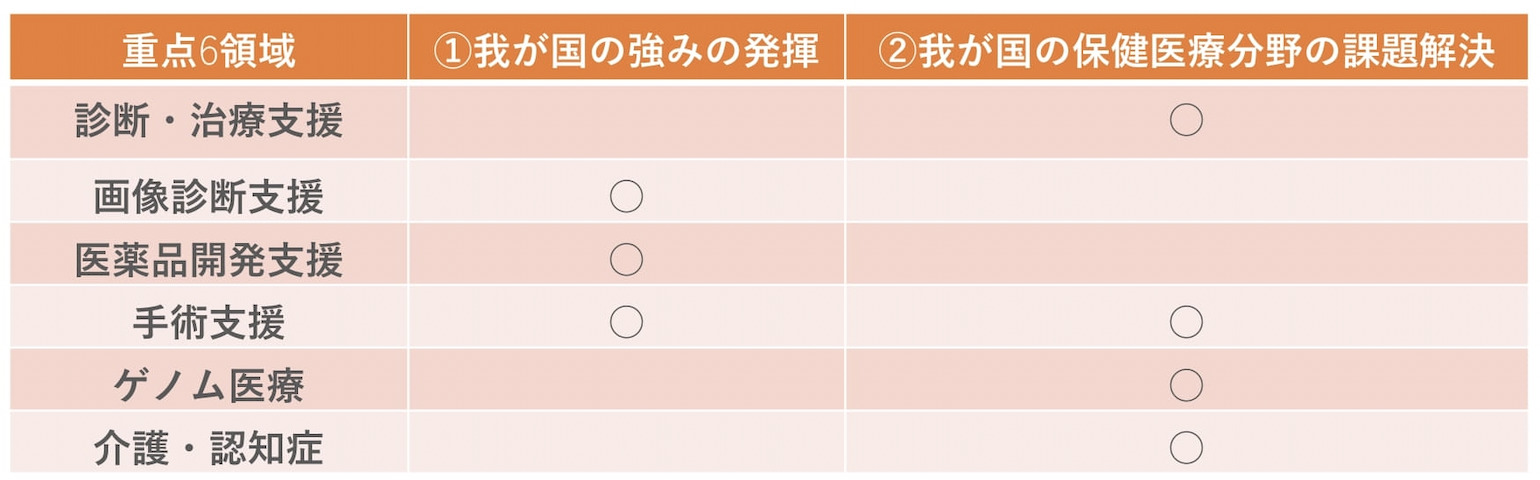
1.診断治療支援
診断治療支援領域での応用は幅広く、適切な治療法を提案するものや、医師の情報収集をサポートするもの、音声やチャットで自動問診を行うものなど、さまざまなサービスが提供されています。そうした機械学習を利用した診断治療支援サービスの一つに「造血幹細胞移植時のドナー/レシピエントマッチングシステム」があります。このサービスは、臍帯血バンクや骨髄バンク等の移植ドナーの情報とレシピエントである患者のデータや前処置情報から、個々のドナー候補に応じて患者の予後を予測するサービスです。医師はこのサービスを利用することによって、最適なドナー候補の選択が可能になり、患者がGVHD(graft-versus-host disease:移植片対宿主病)といった重篤な副作用を引き起こすリスクを下げることができます。このサービスに利用される機械学習モデルは、1年後のGRFS(再発、副作用の無い生存状態)予測において、既存手法であるCOX比例ハザードモデルを越える精度を誇っています。
2.画像診断支援
画像診断支援領域では、機械学習や深層学習による画像処理技術を用いて、画像データによる病気の有無や種類、グレードの予測(画像分類)や、画像データにおける病変や臓器に当たる箇所の描出(領域抽出)などが行われています。
【画像分類】
画像分類の技術を用いて画像診断支援を行っている例として、「細菌感染症菌種推定アプリ」を紹介します。このサービスは、光学顕微鏡にスマートフォンを取り付けることで、検体のグラム染色画像から菌種の推定を行うサービスです。このサービスは、医師が菌種に応じた適正な抗菌薬の処方することを可能にするだけでなく、不適切な抗菌薬の投与を減らすことによる薬剤耐性(AMR:Antimicrobial Resistance)の発生を抑制にも貢献しています。(詳しくはこちら)
【領域抽出】
領域抽出の技術を用いて、画像診断支援を行っている例として「不妊治療における生殖補助医療支援システム」と「血球細胞の分類支援システム」を紹介します。
「不妊治療における生殖補助医療支援システム」は、胚タイムラプス画像から胚の生育過程特徴量(時点特定、面積)を抽出し、染色体異数性を判定するサービスです。医師はこのサービスの利用により、迅速かつ非侵襲的に胚の染色体異数性を判定することが可能になります。このサービスによる胚の染色体異数性の特定は、従来のPGT-A法(Preimplantation genetic testing for aneuploidy)のように胚への侵襲による妊娠・出産率への影響を低減出来るだけでなく、医師・胚培養士が胚タイムラプス画像から胚の生育過程特徴量を抽出する作業負担を減らすことが可能です。(詳しくはこちら)
「血球細胞の分類支援システム」は、骨髄スメア画像から、血球細胞を自動的に検出・分類し、各血球の数を集計するサービスです。 このシステムでは、血球細胞の検出・分類するステップで深層学習が利用されています。臨床現場において、骨髄スメア画像の血球を分類しカウントする作業は、患者あたりスメア画像の約500箇所の観察が必要で、分類対象となる細胞種も30種超あるため、技師負担が大きく、判定精度も経験に依存することが問題視されていた。当サービスはこうした課題を解決し、血球分類作業の大幅な効率化が期待できます。(詳しくはこちら)
3.医薬品開発
医薬品開発領域では、創薬におけるタンパク質と化合物の結合を予測するシステムや、ビッグデータから創薬に必要な情報をピックアップするシステムなどが公開されています。前者の例として、現在臨床試験フェーズの免疫腫瘍薬において、その開発過程で膨大なタンパク質と化合物の結合可否を調べたデータを用いた標的分子との結合を予測するシステムが利用されています。また後者の例として、医薬論文ビッグデータに対して自然言語処理を行い、疾患と遺伝子変異の関係や薬剤とアウトカム指標の関係を分かりやすく構造化して表示するサービスなどが開発されています。
4.手術支援
手術支援領域では、画像解析による術中の手技シュミレーションや、近年利用が拡大している手術支援ロボットを用いた手術サポートなどに機械学習の技術が利用されています。たとえば前者では、腹腔鏡下手術における術中写真に専門医が病変部などの重要領域に目印をつけたデータから、胃がん手術のナビゲーションを作成するAIモデルが登場しています。また後者では、縫合の画像を繰り返し学習させることで手術支援ロボットに手術後の縫合を自動で行わせるものなどの開発が進められています。
5.ゲノム医療
個別化医療に繋がる新しい技術として脚光を浴びているゲノム解析は、遺伝子から膨大な量のゲノム配列情報を読み取る高速シーケンサーの登場により活発になりました。ゲノム情報のようなビッグデータは、コンピュータのよって自動で大量の情報を高速に処理できる機械学習と相性が良く、機械学習を用いてゲノム情報の解析する手法が多数提案されています。たとえば、ゲノムデータを解析して遺伝子変異を発見するシステムや、ゲノム構造の特徴を抽出するシステムなどです。前者の例として、世界中で公開された新型コロナウイルスのゲノムデータを解析し、遺伝子変異を発見するアプリケーションが公開されており、このシステムは変異株の迅速な発見および構造の特定に大きく貢献しました。
6.介護・認知症
介護や認知症は、今後少子高齢化が加速する日本において重大な社会問題です。こうした介護・認知症領域においても、介護者および医療従事者の負担を減らすことを目的に、機械学習を利用したサービスの提供が進んでいます。介護をサポートするサービスには、画像データやベッドの内蔵されたセンサーの情報をリアルタイムで解析することによって、要介護者が転倒等のリスクがある行動を起こした際にアラートを出してくれる見守りロボットなどの普及が進んでいます。また、認知症患者の診断をサポートするサービスには、患者との会話を記録した音声データに対して自然言語処理とテキスト解析を行い、患者が認知症かどうかを判断するサービスなどが登場しています。
このように、さまざまな医療領域で機械学習を利用した新しいサービスが発表され、今後の更なる発展が期待されています。しかし、機械学習と一口にいっても、その細かい手法は学習に使用するデータや学習の目的によってさまざまです。今後、より具体的な機械学習手法について紹介します。