
機械学習におけるImage Segmentationとは画像をいくつかの領域に「分割」するタスクを指しています。Image Segmentationでは、画像を構成する一つ一つのピクセルに対してクラス分類を行います。そして分類されたクラスに割り当てられたピクセル値を表示することで、領域ごとに異なる色で塗り分けられた画像を出力します。Segmentationタスクは、ピクセルのクラス分類の仕方によってSemantic Segmentation、Instance Segmentation、Panopic Segmentationの3タイプに大別されます。
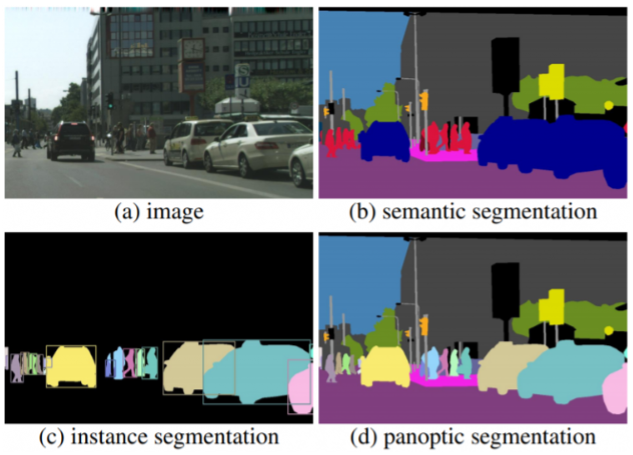
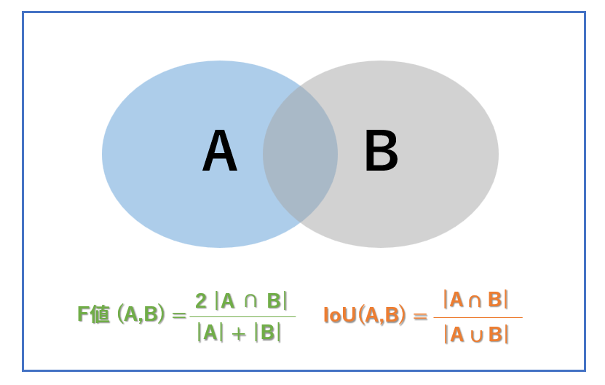
Semantic Segmentationは塗り絵のように画像を構成する全てのピクセルに対してクラス分類を行うタスクです。(図1.b) Semantic Segmentationは、空や道といった物体として数えられないクラスの領域分割も行える一方で、車や人のような数えられるクラスに対して、同じクラスの領域として認識するため、物体ごとの認識・カウントができないという特徴があります。そのため、画像に映る全てのものに対して領域分割したい場合は適していますが、捉えたい物体が決まっていて、それらを個体ごとに区別したい場合には適していません。Semantic Segmentationの評価関数には、一般的に各領域の重なり具合を評価するF値(Dice係数)やIoU(Jaccard係数)などが使われます。F値とIoUはそれぞれ、教師データでラベル領域をA、モデルが予測した領域をBとしたときに図2のような式で表されます。IoUの方が評価が厳しいため、輪郭のはみ出しなどをより厳密に評価したい場合はIoUを使い、細部の情報を重要視しない場合はF値を使います。
Instance Segmentationは対象となる物体(領域)を個別に分割し、かつ物体の種類を認識します。図1を見るとSemantic Segmenttation(b)では車や人がそれぞれすべて同じ色で塗分けられているのに対し、Instance Segmentation(c)では車や人を重なりを加味して正しく別々に検出しています。また、対象の候補領域、すなわち RoI(region of interest)に対して segmentation を行うので、画像全てのピクセルに対してクラス分類を行っていません。そのため、Segmenationしたい領域が決まっていて、それを個体ごとに認識したりカウントしたりしたい場合は適していますが、背景などの数えられない領域まで分割したい場合には適していません。Instance Segmentationの評価関数には、物体検出と同様に mAP(mean average precision) などが使われます。(mAPについては次回記事 “Object Detection” でご紹介します)
Panopic SegmentationはSemantic Segmentation と Instance Segmentation を足し合わせたようなタスクです。図1(d)を見ると、Semantic Segmentation のように全てのピクセルにラベルが振られており、かつInstance Segmentationのように数えられる物体に対して個別で認識していていることが分かります。Panopic Segmentationでは、数えられるクラス(車や人)であるThingクラスに対してはInstance Segmentationを、数えられないクラス(空や道)であるStuff クラスに対してはSemantic Segmentation を行っています。評価指標には、PQ(panoptic quality)が使われており、これはSQ( segmenation quarity)とRQ(recognition quarity)の掛け算によって算出されます。

Image Segmentationのモデル構造は、FCN (Fully Convolutional Networks) 型、Encoder-Decoder型、ピラミッド型、Transformer型の4タイプに大別されます。FCN型は初期に提案されたモデルで、現在はエンコーダ・デコーダ型やピラミッド型が主流です。しかし、最近登場したTransformer型もそれらに匹敵する精度を出すこともあり、注目を集めています。ここでは各タイプにおいて代表的なモデルを紹介します。
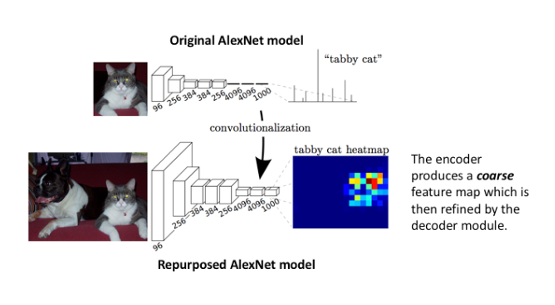
FCNは画像部分類で利用されるCNNをSegmenationに取り込んだモデルです。図3は上半分でCNN型の画像分類モデル、下半分でFCN型のImage Segmentationモデルの模式図を示しています。画像分類モデルでは畳み込み層の後に全結合層を経て画像のクラス予測を出力するのに対し、Image Segmentationモデルでは最後の畳み込み層で得られた特徴マップを入力画像と同じサイズまでアップサンプリングすることでピクセルごとのクラス予測を出力します。しかし、FCN型は畳み込み層により抽象化された特徴マップをそのまま引き延ばしているため、隣接するピクセル同士の関係性を学習しない、領域の境界が曖昧で解像度が低いという欠点があります。
エンコーダ・デコーダ構造のモデルは、畳み込み層によって画像から特徴を抽出するエンコーダと、抽出した特徴を受け取り確率マップを出力するデコーダで構成されます。エンコーダ・デコーダ型で有名なモデルにはU-netなどがあり、このモデルは様々なImage Segmentationタスクに利用されています。
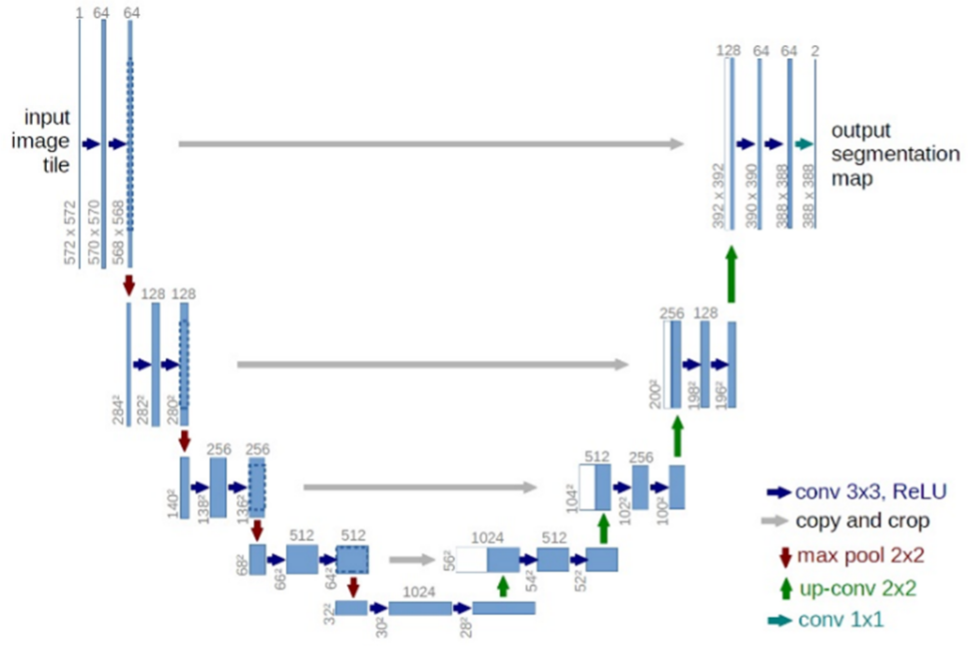
U-netは医用画像のImage Segmentationを目的に考案されたモデルです。ネットワーク構造がU字となっていることがその名の由来で、U字の左半分がエンコーダ、右半分がデコーダです。エンコーダでは畳み込み層とMax Pooling層を使って画像から段階的に特徴を抽出しており、デコーダでは、アップサンプリングと畳み込み層を使って抽出したデータから画像データを復元しています。このときエンコーダ各層での出力を、対応するデコーダ各層での入力に連結することで正確な位置情報を復元し、高解像度の出力を実現しています。
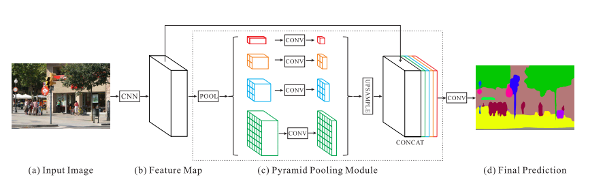
ピラミッド構造のモデルは、サイズの異なる複数のフィルタをネットワークに組み込んでいます。サイズの異なるフィルタを大きいものから順に積み上げるとピラミッドのように見えることから、ピラミッド構造と呼ばれます。これにより様々なスケールの特徴を捉えることが可能になり、今までのSegmenationタスクの課題であった小さすぎる物体や大きすぎる物体、シーン全体の学習を可能にしました。シーン全体の学習によって、たとえば湖の領域のなかに車の領域があるというようなありえない状況を出力する可能性を減らすことができます。ピラミッド型で有名なモデルには、複数のサイズでプーリングするPSP-netや複数のサイズで逆畳み込みを行うDeeplab v3+などがあります。
PSP-net [4]
PSP-netではピラミッド型プーリングが提案されています。まず画像全体に対して畳み込みを行い、異なるカーネルサイズでプーリングを行います。その後それぞれのサイズの特徴マップに対して畳み込みを行い、アップサンプリングしたものをプーリング前の特徴マップに連結して畳み込みます。このアプローチによって様々なスケールの画像の特徴を効率的に学習することを可能にしています。
Transformerは自然言語処理分野で飛躍的な精度向上を達成し、現在のデファクトスタンダードになっているモデルです。近年、Transformerを画像処理分野にも適用する試みがなされており、Image Segmentationタスクに応用したものにSegFormoerなどがあります。
SegFormorは2021年10月に発表されたばかりの最新モデルです。従来の手法と比較して計算コストが低いにも関わらず、ADE20KとCityscapesといったデータセットで従来の手法を上回る精度を記録しています。SegFormorはエンコーダに階層構造のTransformerを用いることでマルチスケールの特徴量を出力しており、またデコーダに各出力を組み合わせるシンプルなMLPを用いることで高度な表現量を出力できるようにしてます。
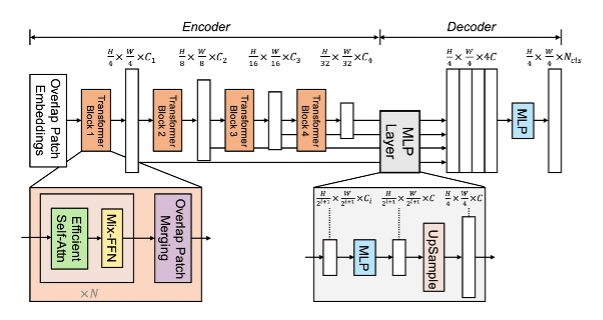
Image Segmentationは出力が画像であるため、予測結果から観察対象がどこにあって、どのような形状をしてるのかを視覚的に確認することができます。これは、医用画像から医師が病変の位置や大きさを把握するのに役立ちます。そのためMedcal Imagingの分野ではImage Segmentationを利用した様々なソフトウェアの開発が進んでいます。
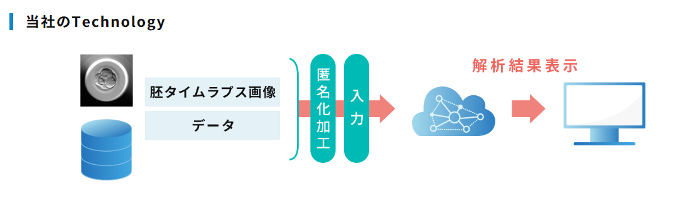
私たちが提供する「不妊治療における生殖補助医療支援システム」にもImage Segmentationの技術が使われています。このシステムは胚タイムラプス画像から胚の生育過程特徴量(時点特定、面積)を抽出して染色体異数性を判定しています。これにより受精しにくい胚を見分けて体外受精の成功率を上げることができます。このシステム内ではInstance Segmentationが行われており、胚のタイムラプス画像から雌性前核、雄性前核の領域を抽出しています。そしてモデルが抽出した胚領域の情報と撮影時のデータから胚の生育スピードや面積を算出しています。Instance Segmentaionモデルの構築にあたっては、これまでに数百症例・数万枚の画像を対象に後向き観察試験を実施し、医師・胚培養士がラべリングしたタイムラプス動画を教師データとして利用しています。システム利用時には体外・顕微受精の胚培養のタイムラプス画像をクラウドサーバー上に配置した画像領域抽出AIに接続したソフトウェアに読み込ませることで、染色体異数性の判定情報を医師に提供します。
以上、Image Segmentationの種類やモデルについて、当社の取り組みも交えて紹介しました。Image Segmentationは汎用性が高く、医用画像との親和性も高いので今後もさらなる発展が期待されます。ぜひ最新情報をキャッチして、研究や業務に活かせそうなものを探してみてください!次回は ”object detection(物体検出)” について解説します。