
深層学習における予測のUncertainty(不確実性)とは、さまざまな確率的要因によって発生する予測のばらつきの程度のことを言います。または、予測の信頼度の指標と捉えることもできます。つまり、予測のばらつきが大きいほど、予測の信頼度は低く、不確実性は高いということです。例えば、回帰問題で予測値がとる値の幅が広いときや、分類問題でクラス毎の確率分布の差が小さいときなどは、予測がばらついており不確実性が大きいと言えます。(図1)
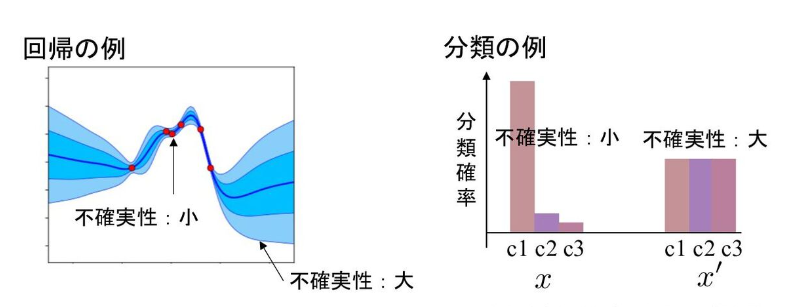
図1:回帰問題と分類問題の不確実性 [1]
機械学習モデルを含むシステム(以下、MLシステム)を運用するにあたって、不確実性の存在を理解しておくことは非常に重要です。なぜなら、不確実性を示すことが予測の透明性や信頼性の向上に繋がるからです。そのため、不確実性はMLシステムの品質管理プロセスにおける様々なフェーズで利用されます。MLシステムの品質管理を行うために規定された標準プロセスの一つにCRISP-ML(Q) [2] というものがあります。正式名は ”Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology” であり、日本語に訳すと「品質保証方法論を備えた機械学習アプリケーション開発のための業界横断的標準プロセス」という意味になります。これはMLOps [3] にも組み込まれており、以下のようなMLシステムの運用フローの中で品質管理を行います。(図2)
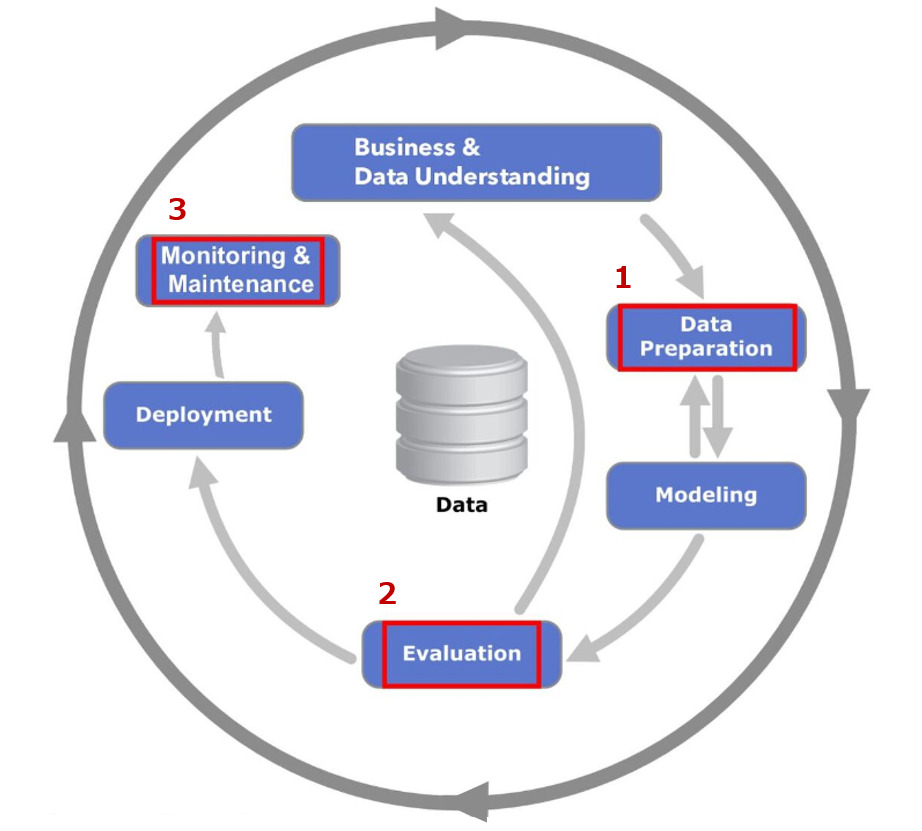
図2:CLISPーML(Q)と不確実性の活用ポイント
CRISP-ML(Q) プロセスの中で、不確実性は 、1. データの準備、2. 評価、3. 監視・メンテナンスのフェーズにおいて以下のように活用できます。
1.データの準備
不確実性が高いサンプルに応じて、再ラベリングや学習データのドメイン調整を行う
2.評価
不確実性が高い場合、予測の信頼度が低いとみなして結果を利用しない
3.監視・メンテナンス
推論時に不確実性の高いサンプルが増えた場合、モデルの劣化とみなして再学習を行う
このように、予測の不確実性はMLシステムの最適な運用に向けて様々な意思決定に関わっています。
では、そもそも不確実性はどうして発生するのでしょうか? 不確実性はデータの獲得、モデルの学習、推論のタイミングで発生し、その要因は大きく5つに分類されます。
要因Ⅰ:現実世界の変動性
現実世界の環境は非常に変動しやすく、モデル学習はほぼ常にこうした変動の影響を受けます。たとえば昼と夜で見え方が全く異なる画像や、気候変動や社会情勢の変化、人間の行動変容などによるパラメータの変化は不確実性に影響します。
要因Ⅱ:測定システムの誤差とノイズ
測定値自体が不確実性の原因となる可能性があります。 例えば、解像度やノイズ、ブレ、センサの経年劣化などによって測定値が予測に十分な情報をもっていないとき、不確実性は高くなります。 また、誤ったラベル付け(ラベルノイズ)もこれに含まれます。
要因Ⅲ:モデル構造のエラー
モデル構造(層数、ユニット数、活性化関数)は精度に直接的な影響を与え、予測のばらつき(不確実性)にも大きく関与します。
要因Ⅳ:訓練プロセスのエラー
訓練プロセスにおけるパラメータ (バッチサイズ、オプティマイザー、学習率、停止基準、正則化など) の違いによって、予測結果にばらつき(不確実性)が生まれます。 特に不均衡データやサンプル数が少ないデータを使った訓練は最適な学習パラメータを見つけるのが難しく、予測の不確実性を高めます。
要因Ⅴ:未知データによるエラー
ネットワークは特定のタスク用にトレーニングされているため、トレーニング時と異なる入力はエラーを引き起こして不確実性を高めます。
これらの要因を、衛星画像を集落と森林に分類する深層学習モデルの例で確認してみましょう。(図3)要因 I は、雲に覆われた画像があったり、季節によって森林の外観が異なったりすることです。要因 II は、集落と森林に分離しきれない画像(両方映っている、解像度が低いなど)やラベルノイズなどがあることです。要因Ⅲはモデル構造、要因Ⅳは訓練プロセスの問題で、要因Ⅴは、学習済みモデルに衛星画像以外を入力するようなことです。
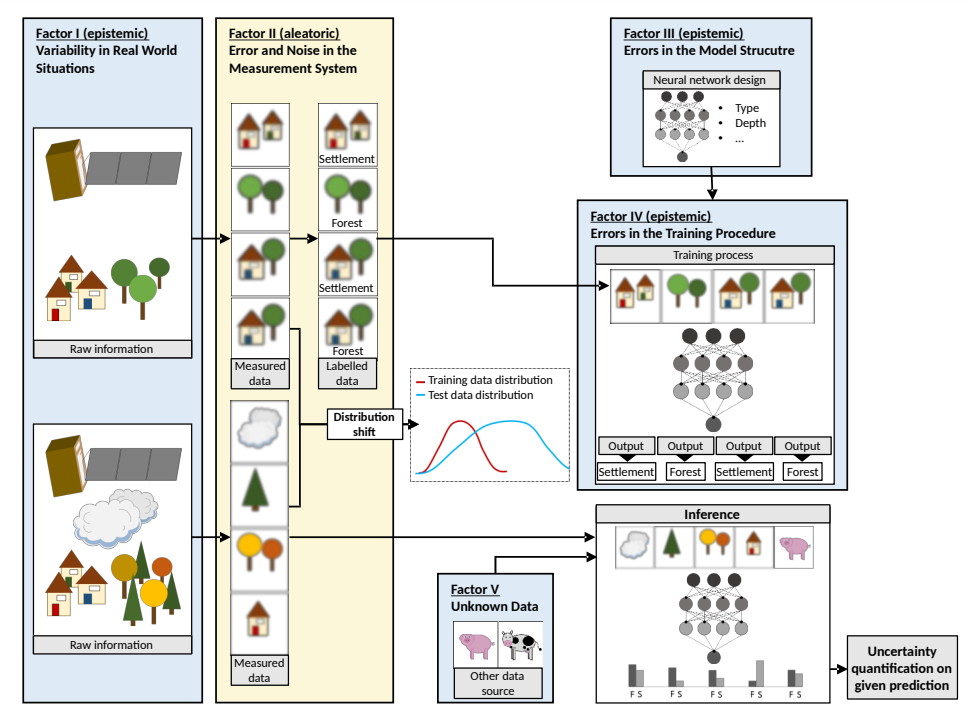
図3:不確実性の5つの要因 [4]
不確実性はその要因によって、Data Uncertainty、Model Uncertainty、Distribution Uncertaintyに分類されます。
測定値の感度不良やラベルノイズといったデータの不確かさ(要因Ⅱ)によって引き起こされる不確実性です。データ自体が原因のため、データを増やしても不確実性は下がりませんが、センサーの変更やデータクリーニング、再ラベリングを行うことで下がる可能性があります。
学習データの不足(要因Ⅰ、V)や不適切なモデルの使用(要因Ⅲ)、誤った訓練(要因Ⅳ)といったモデルの学習方法が原因で生じる不確実性です。学習データの網羅性を高めたり、モデルやそのパラメータを変更することで不確実性が下がる可能性があります。
テストデータと訓練データ分布の不一致(要因Ⅰ、Ⅴ)による不確実性です。 分布が少しズレている程度であれば再学習やドメイン適応によって解消されます。一方で、 分布が全く異なる場合には、でたらめな予測結果を信じないように入力が分布外であることを検知する必要があります。このように、学習データセットにないデータを検知することをOOD(Out-of-distribution)検出と言います。
以下では、回帰問題(上段)と分類問題(下段)における、Data Uncertainty(左)、Model Uncertainty(真ん中)、Distributional Uncertainty(右)を可視化しています。Data Uncertaintyは、回帰問題においてデータのばらつきが大きいとき(左上)や、分類問題において分類境界が曖昧なとき(左下)に高いことが分かります。一方でModel Uncertaintyは、モデルの違いによって予測がばらついたり(真ん中上)、分類結果が異なるとき(真ん中下)に高いことが分かります。またDistributional Uncertaintyは、未知のデータ(Out-of-distribution)が入力されたときに高くなります。
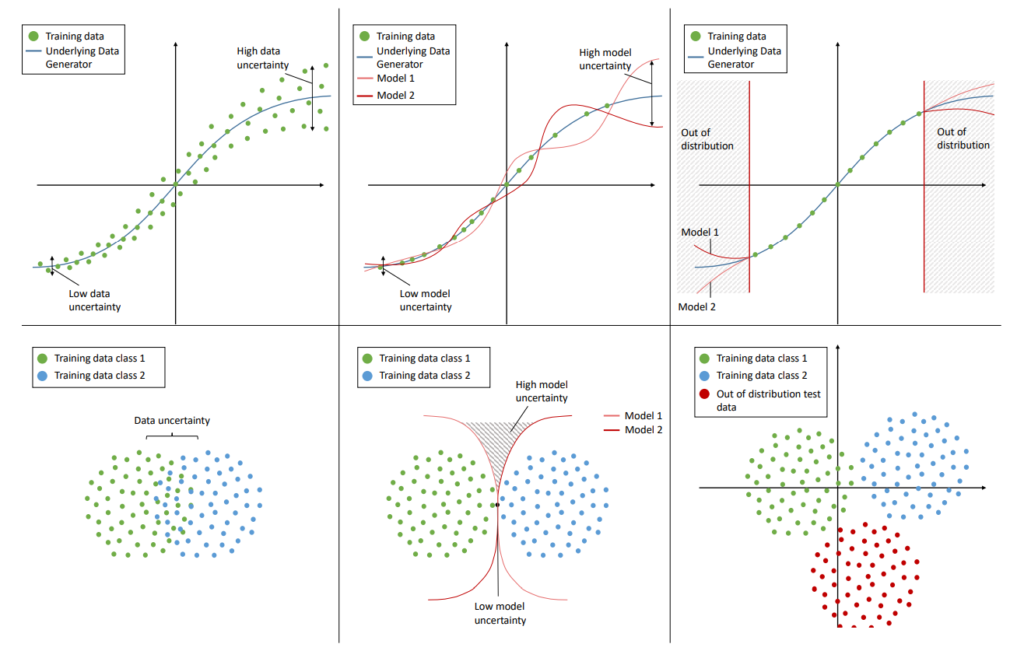
図4:Data Uncertainty, Model Uncertainty, Distribution Uncertainty の比較 [4]
不確実性を評価し、MLシステムの改善に繋げるには不確実性を定量化する必要があります。一般に、不確実性の定量化手法は、使用される DNN の数 (単一または複数) と性質 (決定論的または確率論的) に基づいて、4 つのタイプに分けることができます。(図5)
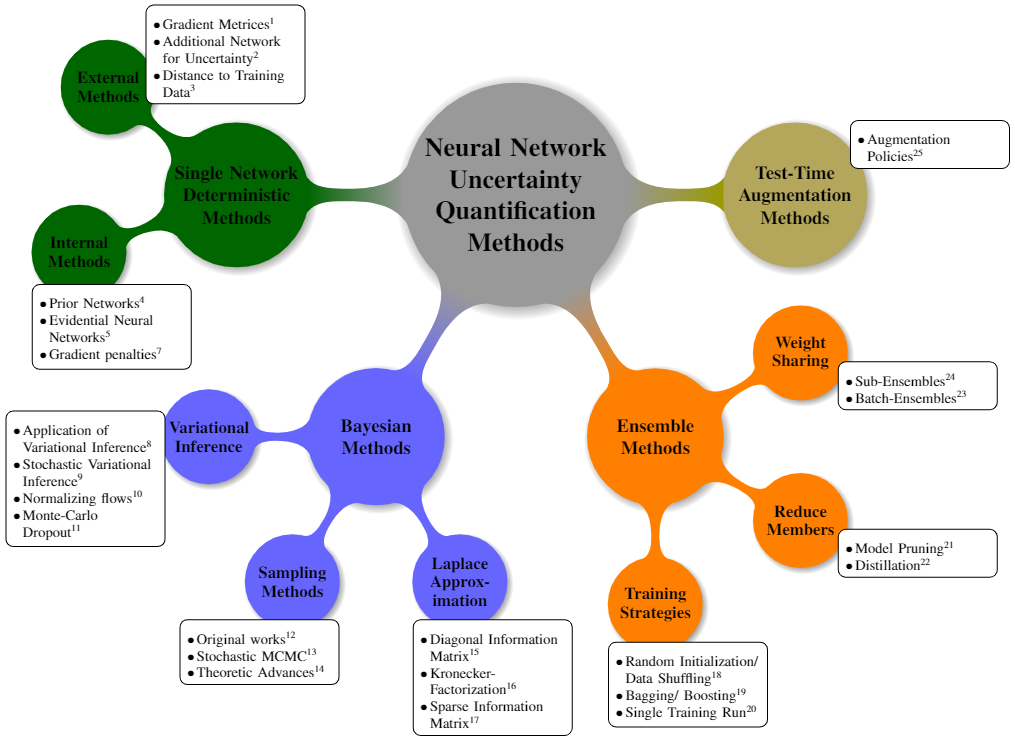
図5:不確実性の定量化手法の分類 [4]
A. 単一決定論的手法(図7、A)
一つの決定論的モデル(初期条件を決めれば、将来が一意的に決定するモデル)の一つのフォワードパスに基づいて計算します。各タスクごとにモデルを設計する必要があるため汎用性は低いですが、推論時間は短くなります。分類問題におけるディリクレ分布を計算する手法では、不確実性とその原因を視覚的に理解することができます。例えば、犬・猫・豚の画像分類モデルで、①犬の画像、②犬・猫・豚が全て映った画像、③象が映った画像に対してそれぞれ、ディリクレ分布をグラフにすると以下のようになります。
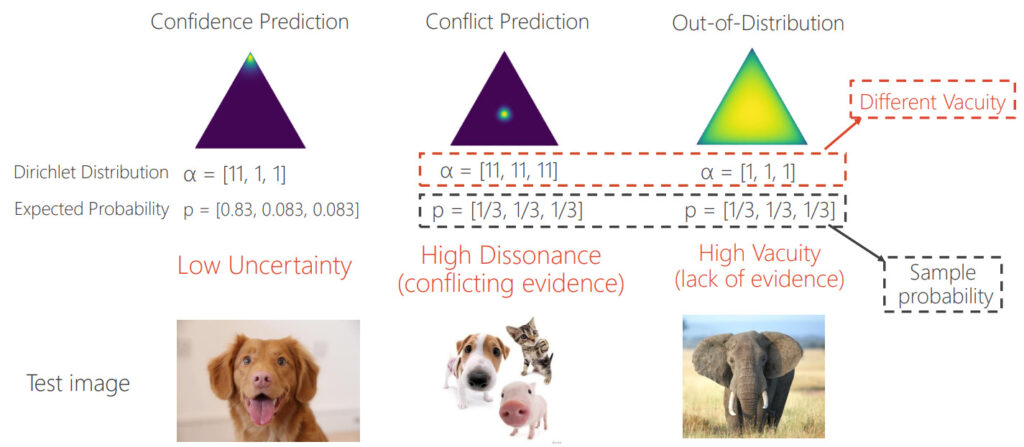
図6:画像分類問題におけるディリクレ分布の可視化 [5]
①は、犬のディリクレ分布のみが高く、三角の一つの頂点のみ強度が高くなります。②は犬、猫、豚全てのディリクレ分布が高く、三角形の真ん中で最も強度が高くなります。③は、どのディリクレ分布も大きなピークを持たないため、全体に分布が広がります。②と③の間でカテゴリ間の確率分布に差がない点は共通していますが、ディリクレ分布は異なっており、②はdata uncertainty、③はdistribution uncertaintyであることが分かります。
B. ベイズ法(図7、B)
ニューラルネットワークのモデルパラメータに事前分布を仮定し、ベイズモデリングを行います。しかし、予測分布の計算においてモデルパラメータの事後確率を計算するのは困難であるため、近似推論技術を使う必要があります。近似推論手法には変分推論、サンプリング法、ラプラス近似などの手法があります。
C. アンサンブル法(図7、C)
複数の異なる決定論的モデルを学習させ、予測値を推論時に組み合わせる手法です。複雑な実装やモデルの大幅な変更を必要としないため、簡単に実装することができます。アンサンブル法ではアンサンブルする一つ一つのモデルに多様性を持たせることが重要で、ランダムな初期化やデータシャッフル、データ拡張は多くのタスクで有効であることが分かっています。
D. テスト時データ拡張法(図7、D)
データ拡張により各テストサンプルから複数のテストサンプルを作成し、それら全てのサンプルをテストして予測分布を計算し、不確実性を測定する方法です。追加データを必要とせず、モデルの変更もないため、簡単に実装できます。注意点として、データ拡張によってターゲット分布を外れたデータを生成しないように気を付ける必要があります。
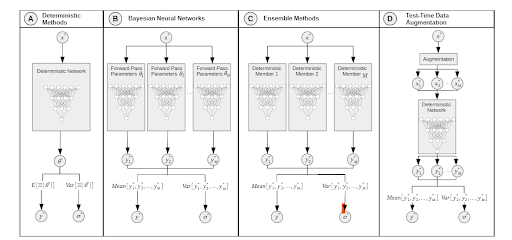
図7:不確実性定量化手法別のネットワークの違い [4]
不確実性は予測の信頼度を明確にするため、医療現場のような予測結果が人の命を左右する重要な意思決定に関わる場面で重宝されます。以下は、IBMがオープンソース化したAIの信頼性を高めるツールキット「Uncertainty Quantification 360(以下、UQ360)」を使って、皮膚疾患診断における画像分類の不確実性を視覚化している例です。
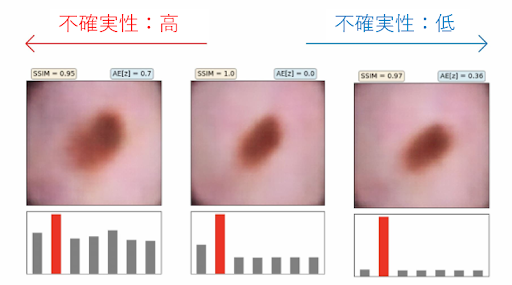
図8:皮膚疾患診断における不確実性の可視化 [6]
左にいくほど不確実性が高い結果になっており、皮膚病変の画像の下にあるバーの高さは、異なる診断に対するモデルの信頼度を示しています。モデルが自信を持っていない場合、臨床医はモデルによる予測を破棄することで、診断ミスから生じるリスクを回避することができます。同様に、創薬のようなケースでも、実世界に先立って薬の候補を不確実性診断機能をもつAIでスクリーニングすることで、創薬のために費やす時間、費用、労力を削減できます。
本記事では、MLシステムを運用する上で理解しておくべき不確実性について解説しました。
不確実性は画像解析や音声認識といった技術に比べると地味に思えますが、あらゆるタスクで効果を発揮する万能で重要な技術です。不確実性の定量化に関しては日々さまざまな手法が発表・議論されているので、興味を持った人はぜひ色々調べて自分の業務や研究に合った方法を探してみてください。
参考文献
[1]‘深層学習における予測の不確実性・入門’, Speaker Deck. https://speakerdeck.com/masatoto/shen-ceng-xue-xi-niokerubu-que-shi-xing-ru-men (accessed Jan. 31, 2023).
[2]S. Studer et al., ‘Towards CRISP-ML(Q): A Machine Learning Process Model with Quality Assurance Methodology’. arXiv, Feb. 24, 2021. doi: 10.48550/arXiv.2003.05155.
[3]‘ml-ops.org’. https://ml-ops.org/ (accessed Jan. 28, 2023).
[4]J. Gawlikowski et al., ‘A Survey of Uncertainty in Deep Neural Networks’, ArXiv, Jul. 2021, Accessed: Jan. 28, 2023. [Online]. Available: https://www.semanticscholar.org/paper/fc70db46738fff97d9ee3d66c6f9c57794d7b4fa
[5]https://zxj32.github.io/data/AAAI-slides-cho%20(1).pdf
[6]42912imag, ‘IBM、AIの不確実性を定量化する「UQ360」をオープンソース化 ~AIの限界と潜在的な失敗点を明示化する「初の包括的なツールキット」’, アイマガジン|i Magazine|IS magazine, Jun. 08, 2021. https://www.imagazine.co.jp/ibm-uq360/ (accessed Jan. 31, 2023).